Overview
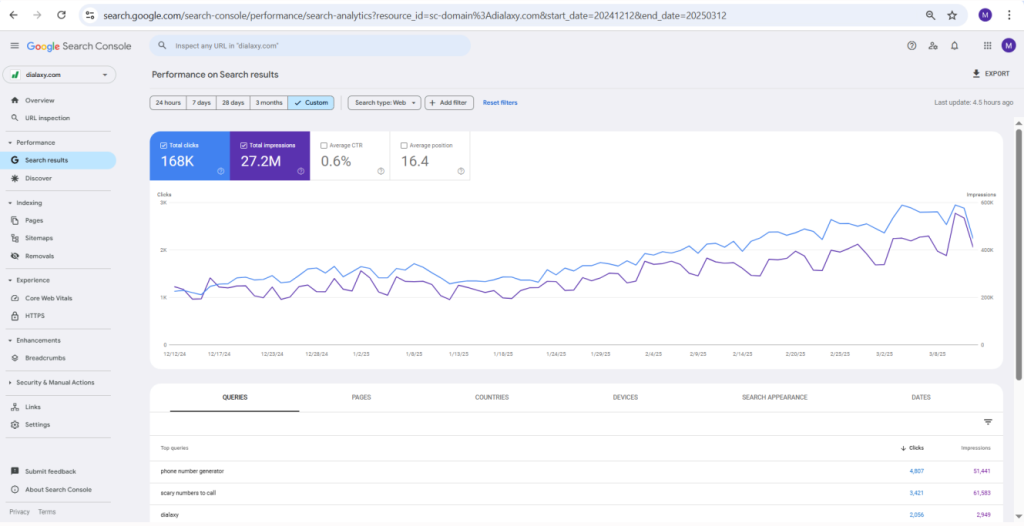
One of the biggest technical SEO challenges I faced while managing GadgetByte Nepal was an enormous number of URLs sitting in Google’s Crawled – Currently Not Indexed bucket.
On April 15, Google Search Console reported:
1,831,707 Crawled – Currently Not Indexed URLs
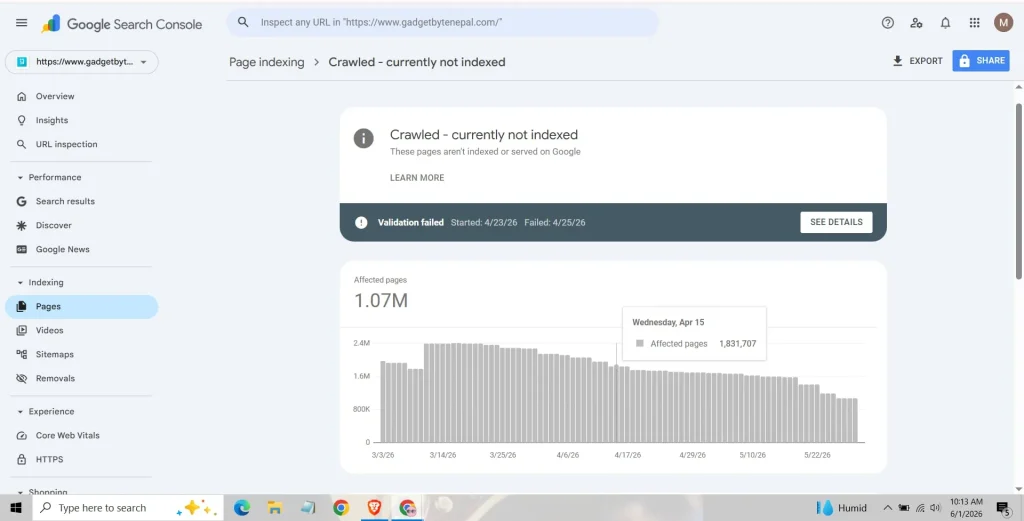
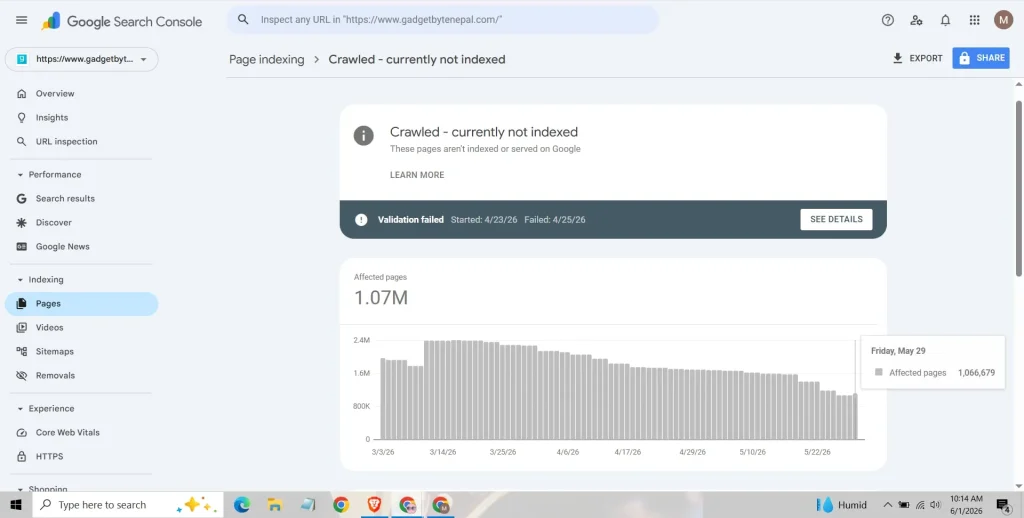
By May 29, I reduced that number to:
1,066,679 URLs
A reduction of:
765,028 URLs in 45 Days
This improvement not only strengthened indexation quality but also helped contribute to the site’s significant organic traffic growth and increased crawl efficiency.
The Problem
Google was spending substantial crawl resources on URLs that it ultimately decided not to index.
This created several problems:
- Crawl budget wastage
- Delayed discovery of important content
- Weak indexation signals
- Duplicate and low-value URL crawling
- Reduced efficiency for new content indexing
For a large publishing website, this can significantly affect organic growth.
My goal was not to force every URL into Google’s index.
Instead, my objective was:
Help Google crawl fewer useless URLs and focus on valuable pages.
Step 1: Search URL Audit
One of the first areas I investigated was search-generated URLs.
These URLs were creating thousands of unnecessary crawl paths.
Actions Taken
- Audited search result URLs
- Identified crawlable low-value search pages
- Recommended robots.txt restrictions
- Reduced Googlebot access to unnecessary URL patterns
This immediately started reducing crawl waste.
Step 2: Parameter URL Cleanup
The site had various parameterized URLs that created duplicate crawl paths.
Examples included:
- Tracking parameters
- Filter variations
- Duplicate URL versions
Actions Taken
- Identified parameter-based URLs being crawled
- Recommended blocking unnecessary parameter patterns
- Reduced duplicate crawl signals
This helped Google focus on canonical URLs rather than endless URL combinations.
Step 3: Fake Pagination Fixes
During technical audits, I identified pagination-related issues creating unnecessary URLs.
Actions Taken
- Audited pagination structure
- Identified fake pagination pages
- Recommended cleanup of low-value paginated URLs
- Improved crawl path efficiency
This reduced Google’s exposure to URLs with little or no standalone value.
Step 4: Canonical Optimization
Many large sites struggle with mixed canonical signals.
I reviewed:
- Canonical tags
- Alternate canonical URLs
- Homepage canonical issues
- Canonical inconsistencies
Actions Taken
- Corrected canonical implementation
- Fixed conflicting canonical signals
- Improved URL consolidation
This helped Google understand which URLs should actually be indexed.
Step 5: Redirect Cleanup
A significant number of internal links pointed toward redirected URLs.
This created unnecessary crawling.
Actions Taken
- Identified redirected internal URLs
- Updated internal linking structure
- Reduced redirect chains
- Removed outdated URL references
As a result, Googlebot could reach destination pages directly.
Step 6: 404 and Soft 404 Analysis
My audits uncovered URLs that were:
- Returning 404s
- Appearing as soft 404s
- Creating unnecessary crawl demand
Actions Taken
- Audited soft 404 reports
- Removed problematic references
- Fixed linking issues
- Improved content quality signals
This reduced Google’s tendency to repeatedly crawl low-value pages.
Step 7: Internal Link Optimization
I discovered that several low-priority URLs were receiving crawl attention due to internal linking patterns.
Actions Taken
- Audited internal link structure
- Reduced links to low-value URLs
- Strengthened links to important pages
- Improved crawl prioritization
This helped redistribute crawl equity toward pages that mattered.
Step 8: Orphan URL and Indexation Review
I performed detailed analysis of:
- Orphan pages
- Noindex pages
- Excluded URLs
- Alternate canonical URLs
Actions Taken
- Mapped important URLs
- Evaluated indexability
- Removed unnecessary crawl paths
- Improved site architecture
This helped create clearer signals for Google.
Results
Crawled – Currently Not Indexed
| Date | URLs |
|---|---|
| April 15 | 1,831,707 |
| May 29 | 1,066,679 |
| Reduction | 765,028 |
Improvement
41.8% reduction in 45 days
Additional Benefits
- Improved crawl budget efficiency
- Cleaner site architecture
- Better indexation signals
- Faster discovery of important pages
- Stronger technical SEO foundation
- Contributed to overall organic traffic growth
Key Takeaway
Many SEOs try to increase indexed pages.
I focused on something more important:
Helping Google stop wasting resources on URLs that never deserved to be indexed in the first place.
Through technical audits, crawl budget optimization, canonical improvements, redirect cleanup, parameter control, search URL management, and internal linking improvements, I reduced GadgetByte Nepal’s Crawled – Currently Not Indexed URLs by over 765,000 in just 45 days, creating a much healthier and more efficient website for long-term organic growth.
This project demonstrates how technical SEO can have a measurable impact even on websites with millions of URLs and an already established organic presence.